
Generative AI Supported Data Modernization
AI Agents as SQL-to-Medallion Migration Experts

Disclaimer: In the post below, I will focus only on the methodological approach of how LLMs can assist in data platform modernization and how this approach is different from the “traditional one.”
Nonetheless, my explanations are backed up by WIP code allocated in the GitHub repo here, so feel free to reuse it.

Most organizations embarking on data platform modernization projects face similar obstacles, and once you start this journey, it feels like you have opened Pandora’s box.
No hope on the horizon, but “bringers of evil” everywhere:
Legacy codebases are undocumented, with critical business logic buried in decades-old code, and no one knows where the data is coming from or who is still using it.
Technical debt has accumulated as systems have evolved organically, creating interdependencies defying easy mapping and lineage.
Data quality issues, inconsistent development standards, security, and regulatory constraints further complicate matters.
On top of this, the human element brings additional challenges.
Teams with expertise in legacy systems sometimes lack familiarity with modern cloud architectures, while cloud specialists struggle to understand the particularities of older platforms. This knowledge gap creates friction and increases the risk of errors and delays during modernization.
Then, there are stakeholders — the visionaries who invested a substantial budget in this expensive initiative and, therefore, expect results sooner than predicted by the project. In some situations, they expect even more to be delivered than initially planned, and as the project evolves, their requirements evolve with it. (But deadlines stay the same).
Even with all the efforts invested in a pre-mortem strategy and building a savvy team of lead, shadow, and sparring experts to pull the project forward, unexpected challenges can prolong the project for months (I fear to say even years).
And even by adopting available data migration tools and plugins, extensive manual effort sometimes can’t be avoided.
In the end, most of the tools are rule-based, and none can cover all the cases you encounter in modernization.
Thus, you often end up analyzing source code function by function, mapping data structures, rewriting business logic, and adapting to the constraints and capabilities of target platforms.
When this is all finalized, and you start thinking you can take a breath of fresh air, the testing phase comes. To hand over the bad news first; it sometimes lasts longer than the development, and engineers struggle with how to automate this process between two different platforms (“the old vs. the new” or “the source vs. the target”). And can you even do the testing programmatically if you change the code and enhance it as well? Or what if you notice the source data model is incorrect and needs to be fixed?
“The joy of re-engineering” — said no project lead, business analyst, data engineer, data scientist, or stakeholder ever.
I just listed what usually happens on small to medium projects, so it’s clear this process doesn’t scale well.
In large enterprises with octopus-like digital ecosystems spanning multiple technologies and decades of development, you need multiple modernization projects.
The longer they last, the more complex they become; you experience human fluctuation, which means you don’t have the constant knowledge and expertise to move from one project to another smoothly.
From my explanations, you understand why these projects fail or don’t even start, although they are very much needed.
Now, regardless of all this complexity, there is a silver lining in the era we live in — the Generative AI era.
Or, as I like to say:
Desperate times call for Generative AI measures.
Joke aside. I am all for Generative AI, but I tend to be conscious of why, where, and when to use it.
Data modernization projects are, for me, this “why, where, and when.”
Let’s exemplify this with one data product that needs to be modernized.

The problem
Imagine you have inherited a stack of analytical products with code that powers your organization’s insights and is served to both internal and external users.
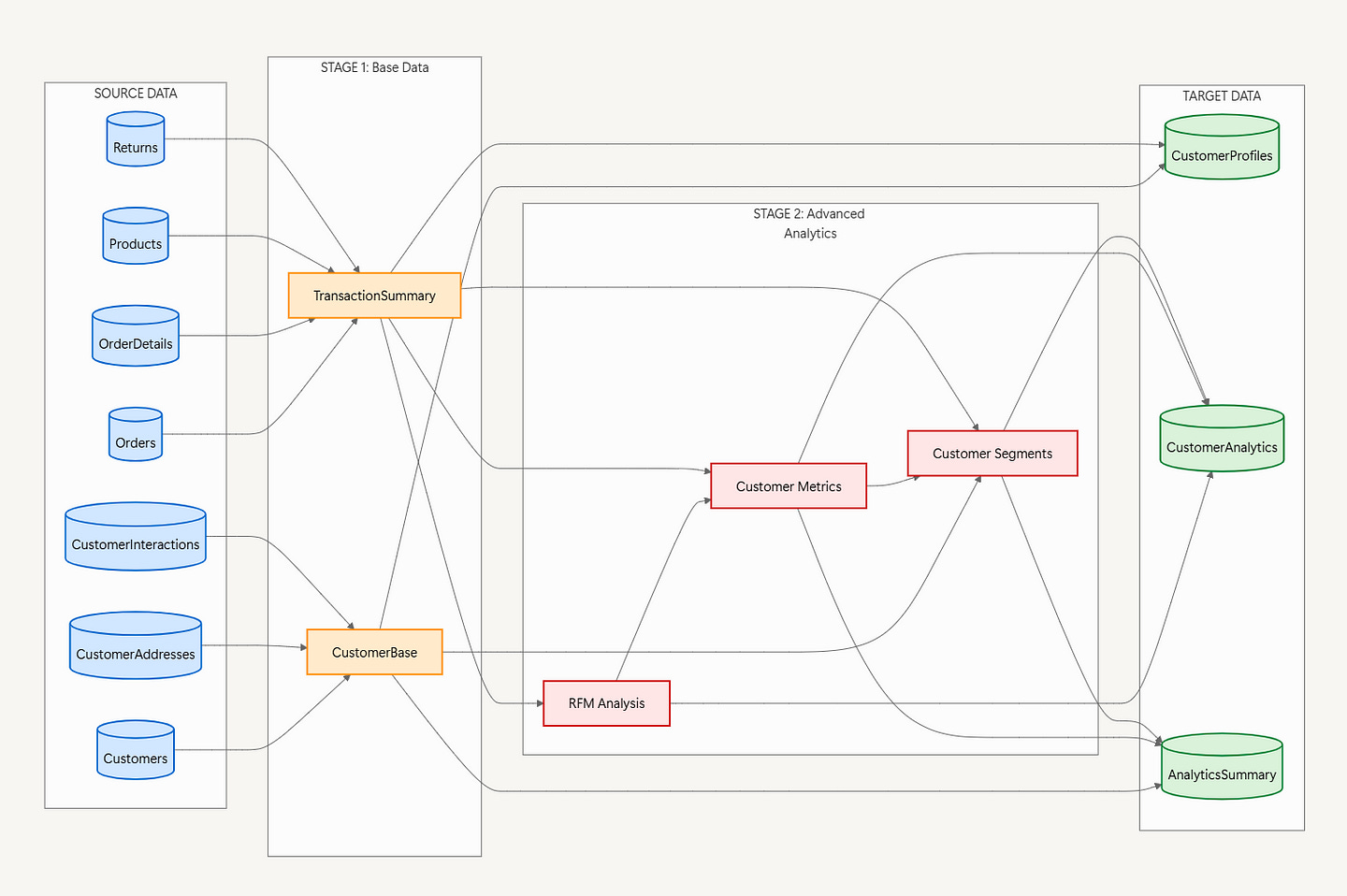
All inherited data products are interconnected, and one of the critical ones is the RFM (Recency, Frequency, Monetary) analysis used for customer segmentation 👇🏼. It’s 700+ lines of SQL code that have been maintained by 3–4 different developers over the past decade.
The business depends on it daily, and modernization is necessary to serve the rising number of users.
The priority is to migrate it to Microsoft Fabric medallion architecture using PySpark while ensuring:
The business logic remains intact,
Performance improves,
The new code follows best development practices,
Documentation is in place,
Testing proves the equivalence of results.
What happens next is you and your colleagues find yourselves staring at a stakeholder who requested a modernization of this product, and you wonder what exactly this business logic is and where is the documentation that should explain it.
On top of missing business knowledge, cloud-skilled colleagues find it challenging to refactor code they barely understand and that has dependencies to other data products, which can easily “break” them.
This means you haven’t even started doing the heavy work yet, but you already have the time disadvantage due to missing legacy knowledge.
Nonetheless, you accept the challenge of modernization by methodically approaching the problem.
In front of you are two options for how to do this…
The traditional modernization process
…would go something similar to:
Business analysis: Spend weeks interviewing engineering colleagues, domain experts and stakeholders who created the RFM data model or use the data insights to understand “where the data is coming from” in the first place. As an outcome, you create numerous knowledge base documents nobody will read.
Technical deep dive: Engage a full team to invest at least two scrum sprints deciphering legacy code with comments like
-- Added by MarvelComicsCharacter to fix the script (Date: 15.05.2018).Architecture planning: Create new diagrams with a new toolset showing how data will flow, knowing how your architecture will completely change before the development starts.
Implementation: Watch the engineering colleagues disappear into a rabbit hole of code for weeks, emerging occasionally on daily Scrum meetings to mutter about “unexpected edge cases.”
Testing: Discover that no stakeholder can confirm whether the new data product is “accepted” because acceptance criteria changed three times during development.
Deployment: Ask the team to work overtime to execute the cutover plan, which, of course, should happen on the weekend.
And then, there is the second approach…
The LLM-powered modernization process
…coming back to 2025, the LLMs can resolve part of the modernization tasks humans would do manually before.
This includes tasks from analyzing and describing the existing development to re-engineering the code for delivering first data product prototypes. And all this work appears as if real humans would interact.
In our specific problem, the human-like collaboration, or agentic workflow, can mimic specialists in different domains contributing their unique expertise to speed up modernization of the legacy RFM data model👇🏼.
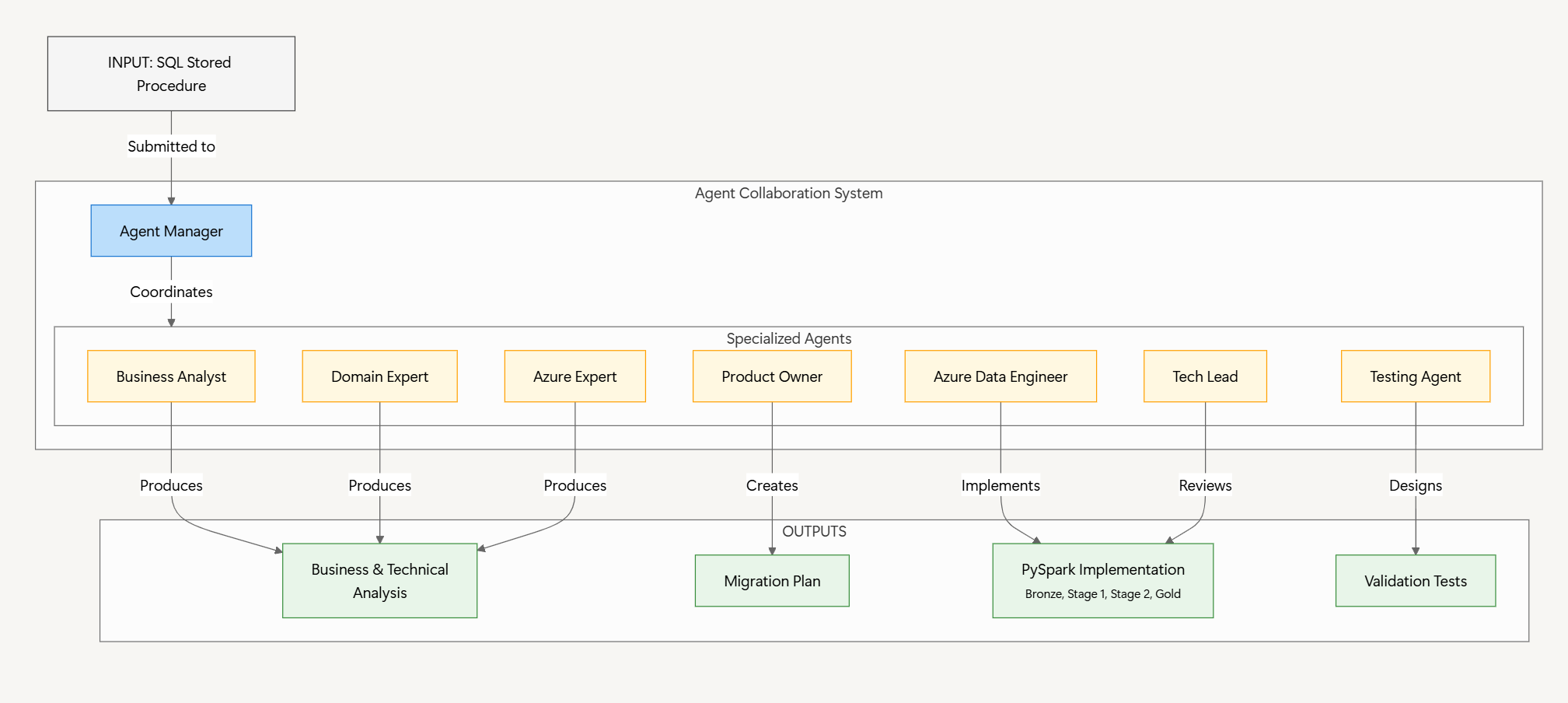
The sql-migration-agents system works like a team of data domain specialists, each bringing unique expertise to the table, transforming the legacy RFM procedure by “calling in LLMs”:
1 — THE INPUT: The MS SQL Stored Procedure
So, instead of manually picking up the legacy code and starting the business analysis yourself, you pass this input to a team of AI-generated data experts with different roles.
This means you need to define the roles and state what is expected from them.
Following the above-mentioned traditional approach, you decide to go for:
Business Analyst: An expert who understands what the legacy code is trying to accomplish from a business perspective, identifying key metrics and business rules embedded in the SQL.
Domain Expert: An expert who analyzes the SQL techniques, subqueries, and procedural logic.
Azure Expert: An expert who recommends Azure data engineering best practices for optimal implementation in the Microsoft Fabric.
Product Owner: An expert who serves as the voice of the stakeholders, prioritizing critical business functionality and validating that the migration preserves business value.
Tech Lead: An expert who designs the architecture of the new solution and patterns for the PySpark implementation.
Azure Data Engineer: An expert who handles the code transformation to PySpark and implements the technical migration.
Testing Agent: An expert who creates validation tests to ensure functional equivalence between old and new implementations.
2 — THE PROCESS: Expert Collaboration
Then, you mimic via code the human-like cooperation and create small crews and “individual contributors”:
The Agent Manager is here to coordinate everything, ensuring the correct information flows between agents.
The Analysis Crew (Business Analyst, Domain Expert, Azure Expert) is here to break down the SQL to understand its purpose, identify complex patterns, and plan the migration approach.
The Product Owner Agent is here to review this analysis, highlighting which aspects of the code must be preserved and which parts might benefit from enhancement in the new implementation.
Based on this prioritized analysis, the Implementation Crew (Tech Lead, Azure Data Engineer) is here to build the new PySpark solution following the medallion architecture best practices.
Lastly, the Testing Agent is here to develop validation tests, following the business requirements highlighted by the Product Owner.
Voila, the team and the environment are now set, and they start interacting and chatting to generate the specified outputs.
3 — THE OUTPUT: Analysis documents and PySpark code
What happens next is that “the team” generates artefacts in the form of the new code and modernization documentation:
Analysis Results: A stack of resources that contains documented business insights, technical SQL breakdowns, and Azure-specific recommendations.
PySpark Code: Python scripts organized into
bronze(raw ingestion),stage 1 base data(initial silver layer transformations),stage 2 analytics(advanced silver layer transformations), andgold layer(final analytics-ready views).Quality Assurance: Test cases validating business equivalence and a recommended migration plan outlining steps needed for deployment.
And just like that, the AI team of experts produces outputs for you that would usually take a month or two of manual work. This gives you a cold start advantage in your project without opening one job advertisement and going through the hiring process.
Well, about this, let’s still not forget the human-in-the-loop “component”...

“Free Flying Lessons”
From the statement “Desperate times call for Generative AI measures” to the reality that working without generative AI is not an option for many of us anymore, it’s good to mention how nothing should yet go without the human-in-the-loop component.
While the agentic approach is great for re-engineering tasks because it addresses the “unknown unknowns” without the need to follow predefined processes, it can still produce inaccurate results and generate more challenges in modernization projects.
Relying on “lossy and probabilistic” models will get you “free flying lessons” at the start, but it’s important to create “review gates” in the workflow where human experts validate AI outputs, particularly for business logic preservation, security requirements, and governance constraints that are not understandable to LLMs.
So, before any LLM-only generated product gets deployed to the target environment, humans need to be included in the approval and review process.
This means the hybrid (or balanced) approach (AI advances + human component) gives the best results:
First, get AI agents to tackle the heavy lifting by generating code prototypes, analyzing complex SQL patterns, and creating documentation drafts that would otherwise take weeks of manual effort.
Then, use these AI drafts as starting points for the engineering team, who will convert them to production-ready solutions.
Summa summarum, there is always more to modernization projects that is not visible to the “AI eye,” and can’t be decoded with LLMs as it is stored in the human brain only.
Thank You for Reading!
If you found this post valuable, feel free to share it with your network. 👏
Stay connected for more stories on Medium ✍️ and LinkedIn 🖇️.